
De-watermark il mio libro #1
Topic:
In questa serie di post condivido i passaggi necessari per rimuovere testi e immagini DRM e watermark da un libro PDF che ho acquistato, in modo da avere una copia stampabile e meglio leggibile.
Setup
- OS1: Debian (su WSL 2)
- Librerie:
sudo apt update sudo apt-get install xpdf qpdf mupdf-tools - OS2: Windows 10
- Software: Foxit Phantom PDF 10.0.0.35798
Walkthrough
 Ancora nessuna manipolazione delle pagine.
Ancora nessuna manipolazione delle pagine.
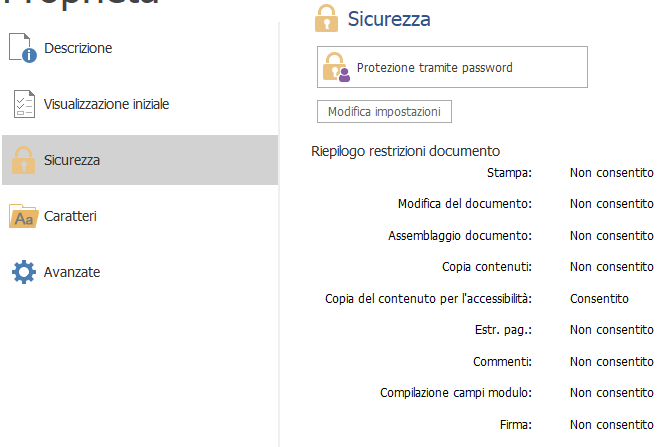 Il PDF dispone di un blocco password che impedisce le principali funzionalità di editing.
Il PDF dispone di un blocco password che impedisce le principali funzionalità di editing.
I watermark che possiamo individuare sono presenti in tutte le pagine: un’immagine centrale e un testo sottostante. Il libro è protetto da una password, il che ci impedisce, tra le altre cose, di stamparlo e modificare oggetti grafici. Un possibile approccio sblocca il PDF e richiede la modifica manuale di ogni watermark in tutte le pagine. Lo escludiamo.
Piuttosto, “corrompo” il PDF sostituendo tutti i riferimenti al watermark immagine con dei riferimenti fittizi.
Preparazione
qpdf --decrypt --stream-data=uncompress input-protected.pdf uncompressed.pdf
Rottura riferimenti watermark immagine
pdfimages -list uncompressed.pdf
La lista delle immagini è presentata di seguito: come possiamo vedere nella colonna object, l’immagine 522x144 (object 11) è presente in ciascuna delle 4 pagine.
page num type width height color comp bpc enc interp object ID x-ppi y-ppi size ratio
--------------------------------------------------------------------------------------------
1 0 image 522 144 sep 1 8 jpeg no 11 0 196 31 8066B 11%
1 1 image 179 266 index 1 8 image no 9 0 101 101 46.5K 100%
1 2 image 298 250 index 1 8 image no 10 0 101 101 72.8K 100%
2 3 image 522 144 sep 1 8 jpeg no 11 0 196 31 8066B 11%
3 4 image 522 144 sep 1 8 jpeg no 11 0 196 31 8066B 11%
3 5 image 376 554 index 1 8 image no 67 0 101 101 203K 100%
4 6 image 522 144 sep 1 8 jpeg no 11 0 196 31 8066B 11%
Entrando più nel dettaglio:
mutool show uncompressed.pdf grep > mutool-show.txt
...
11 0 obj <</BitsPerComponent 8/ColorSpace 8 0 R/Filter/DCTDecode/Height 144/Length 8066/Subtype/Image/Type/XObject/Width 522>> stream
...
Rottura riferimenti all’immagine
Dobbiamo assicurarci che l’oggetto che sostituirà il n. 11 deve avere stessa lunghezza:
sed <uncompressed.pdf >filtered.pdf -e "s/11 0 obj/99 0 obj/g"
Repack
qpdf filtered.pdf output1.pdf
mutool clean -g -g -g output1.pdf output2.pdf
gs -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=output3.pdf output2.pdf
 Risultato finale.
Risultato finale.
Gestione errore error: Unable to find trailer dictionary while recovering damaged file: guida.